GPU-accelerated Analytics
Proteus achieves fast response times and efficient utilization of the available hardware resources. It encapsulates device heterogeneity to enable seamless orchestration across CPUs and GPUs.
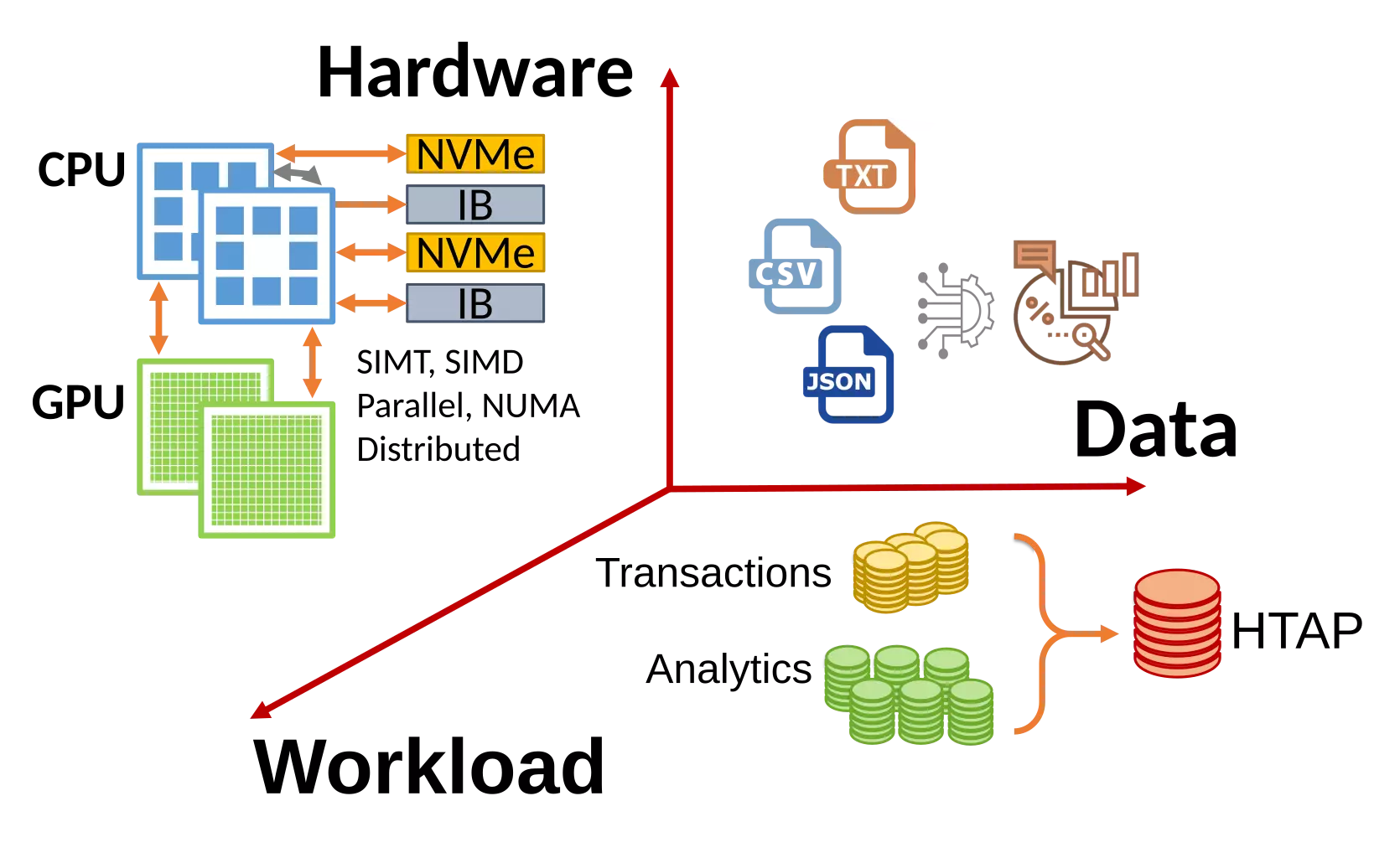
Proteus is a database engine designed for today's heterogeneous environments. Proteus adapts to variable data, hardware and workloads through a combination of GPU acceleration, data virtualization, and adaptive scheduling.
Data, hardware, and workloads are increasingly heterogeneous, challenging existing system designs and slowing down data scientists' exploration cycles.
Proteus uses heterogeneity to unlock optimization opportunities, delivering accelerated operational analytics and reducing the data-to-insights time.
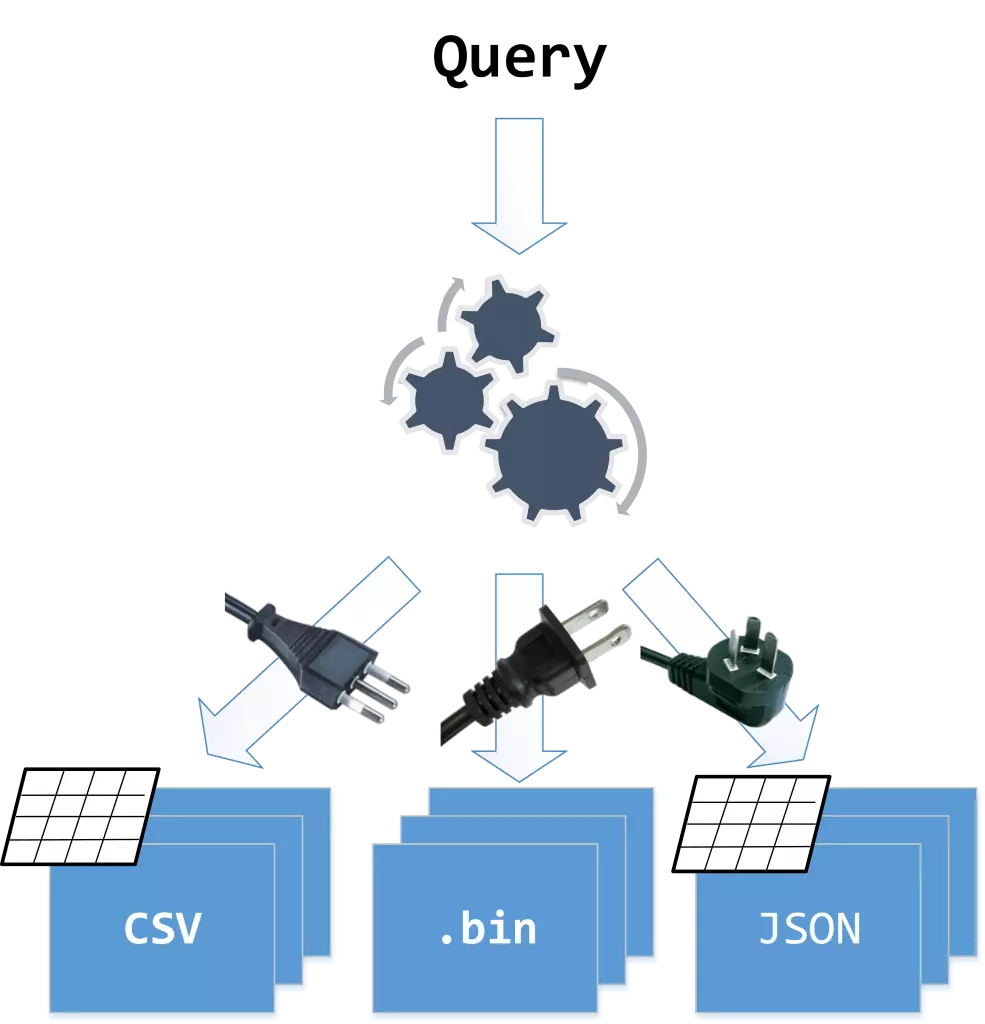
Data scientists rely on a wide variety of heterogeneous datasets to gain insights. The different data models and formats pose a significant challenge in performing analysis over diverse datasets.
Proteus virtualizes the data to provide a uniform operational model while allowing for just-in-time specialization to the data models and formats at hand.
The modern hardware landscape expands beyond CPU-only servers to meet the computational demands. Modern servers have multiple hardware accelerators relying on software exploiting the available hardware resources, challenging existing systems that depend on hardware uniformity, and continuous hardware advances on CPUs.
Proteus exploits accelerator-level parallelism to reduce query response times by orchestrating query execution in multi-CPU, multi-GPU servers and using just-in-time compilation for smoother cross-device operator support.
The velocity of modern workloads generates vast amounts of data that need to be quickly ingested to allow timely business intelligence, pushing the limits of existing static resource allocation schemes for operational analytics.
Proteus exploits workload irregularities to deliver fast insights, while it exploits accelerator-level parallelism to increase workload isolation.
Proteus achieves fast response times and efficient utilization of the available hardware resources. It encapsulates device heterogeneity to enable seamless orchestration across CPUs and GPUs.
Proteus customizes itself on-demand to the data formats and hardware. It uses LLVM-based code generation to JIT (just-in-time) provide highly-optimized specialized engines per query.
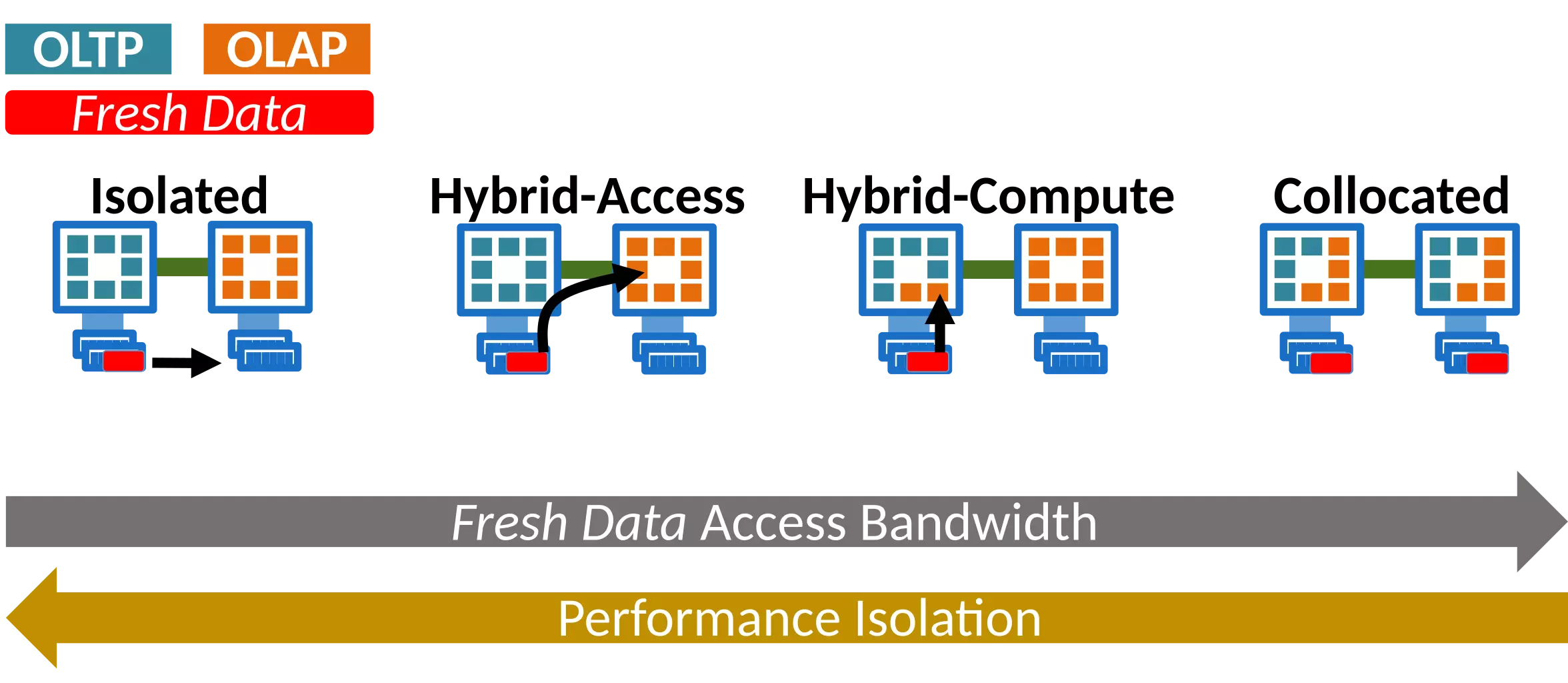
Proteus schedules concurrent OLTP and OLAP based on the amount of fresh data queried by OLAP, and adapts data access paths, compute affinities and snapshot granularity across the OLAP & OLTP engines.
Proteus enables efficient and online data exploration through JIT data summaries. It uses hardware-conscious approximation operators designed for high-bandwidth data processing to unlock interactive data insights.
Proteus minimizes software-level interference across the transactional and analytical engines. It uses the hardware isolation between CPUs and GPUs to bound interference across workloads.
Proteus intelligently caches input data for fast analytics on disk-resident data. Through query- and execution-awareness, it distributes the in-memory space across input data to maximize the overall query speedups.
As the data volume grows, reducing the query execution times remains an elusive goal. While approximate query processing (AQP) techniques present a principled method to trade off accuracy for faster queries in analytics, the sample creation is often considered a second-class citizen. Modern analytical engines optimized for high-bandwidth media and multi-core architectures only exacerbate existing inefficiencies, resulting in prohibitive query-time online sampling and longer preprocessing times in offline AQP systems.
We demonstrate that the sampling operators can be practical in modern scale-up analytical systems. First, we evaluate three common sampling methods, identify algorithmic bottlenecks, and propose hardware-conscious optimizations. Second, we reduce the performance penalties of the added processing and sample materialization through system-aware operator design and compare the sample creation time to the matching relational operators of an in-memory JIT-compiled engine. The cost of data reduction with materialization is up to 2.5x of the equivalent group-by in the case of stratified sampling and virtually free (∼1x) for reasonable sample sizes of other strategies. As query processing starts to dominate the execution time, the gap between online and offline AQP methods diminishes.
Analytical engines rely on in-memory caching to avoid disk accesses and provide timely responses by keeping the most frequently accessed data in memory. Purely frequency- & time-based caching decisions, however, are a proxy of the expected query execution speedup only when disk accesses are significantly slower than in-memory query processing. On the other hand, fast storage offers loading times that approach or even outperform fully in-memory query execution response times, rendering purely frequency-based statistics incapable of capturing impact of a caching decision on query execution. For example, caching the input of a frequent query that spends most of its time processing joins is less beneficial than caching a page for a slightly less frequent but scan-heavy query. As a result, existing caching policies waste valuable memory space to cache input data that offer little-to-no acceleration for analytics.
This paper proposes HPCache, a buffer management policy that enables fast analytics on high-bandwidth storage by efficiently using the available in-memory space. HPCache caches data based on their speedup potential instead of relying on frequency-based statistics. We show that, with fast storage, the benefit of in-memory caching varies significantly across queries; therefore, we quantify the efficiency of caching decisions and formulate an optimization problem. We implement HPCache in Proteus and show that i) estimating speedup potential improves memory space utilization, and ii) simple runtime statistics suffice to infer speedup expectations. We show that HPCache achieves up to 12% faster query execution over state-of-the-art caching policies, or 75% less in-memory cache footprint without deteriorating query performance. Overall, HPCache enables efficient use of the in-memory space for input caching in the presence of fast storage, without any requirement for workload predictions.
GPUs are becoming increasingly popular in large scale data center installations due to their strong, embarrassingly parallel, processing capabilities. Data management systems are riding the wave by using GPUs to accelerate query execution, mainly for analytical workloads. However, this acceleration comes at the price of a slow interconnect which imposes strong restrictions in bandwidth and latency when bringing data from the main memory to the GPU for processing. The related research in data management systems mostly relies on late materialization and data sharing to mitigate the overheads introduced by slow interconnects even in the standard CPU processing case. Finally, workload trends move beyond analytical to fresh data processing, typically referred to as Hybrid Transactional and Analytical Processing (HTAP).
Therefore, we experience an evolution in three different axes: interconnect technology, GPU architecture, and workload characteristics. In this paper, we break the evolution of the technological landscape into steps and we study the applicability and performance of late materialization and data sharing in each one of them. We demonstrate that the standard PCIe interconnect substantially limits the performance of state-of-the-art GPUs and we propose a hybrid materialization approach which combines eager with lazy data transfers. Further, we show that the wide gap between GPU and PCIe throughput can be bridged through efficient data sharing techniques. Finally, we provide an H2TAP system design which removes software-level interference and we show that the interference in the memory bus is minimal, allowing data transfer optimizations as in OLAP workloads.
Modern Hybrid Transactional/Analytical Processing (HTAP) systems use an integrated data processing engine that performs analytics on fresh data, which are ingested from a transactional engine. HTAP systems typically consider data freshness at design time, and are optimized for a fixed range of freshness requirements, addressed at a performance cost for either OLTP or OLAP. The data freshness and the performance requirements of both engines, however, may vary with the workload.
We approach HTAP as a scheduling problem, addressed at runtime through elastic resource management. We model an HTAP system as a set of three individual engines: an OLTP, an OLAP and a Resource and Data Exchange (RDE) engine. We devise a scheduling algorithm which traverses the HTAP design spectrum through elastic resource management, to meet the workload data freshness requirements. We propose an in-memory system design which is non-intrusive to the current state-of-art OLTP and OLAP engines, and we use it to evaluate the performance of our approach. Our evaluation shows that the performance benefit of our system for OLAP queries increases over time, reaching up to 50% compared to static schedules for 100 query sequences, while maintaining a small, and controlled, drop in the OLTP throughput.
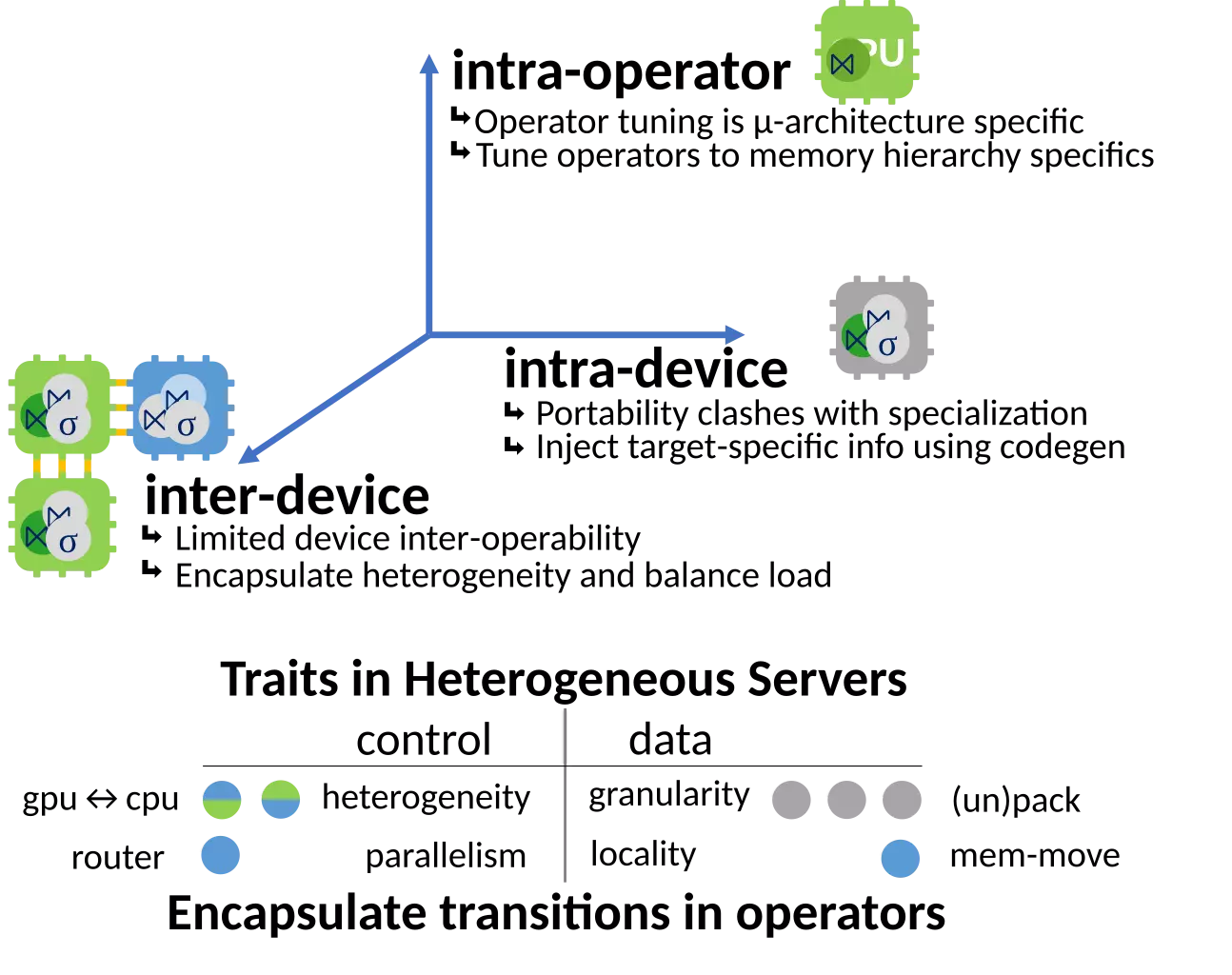
Modern server hardware is increasingly heterogeneous as hardware accelerators, such as GPUs, are used together with multicore CPUs to meet the computational demands of modern data analytics workloads. Unfortunately, query parallelization techniques used by analytical database engines are designed for homogeneous multicore servers, where query plans are parallelized across CPUs to process data stored in cache coherent shared memory. Thus, these techniques are unable to fully exploit available heterogeneous hardware, where one needs to exploit task-parallelism of CPUs and data-parallelism of GPUs for processing data stored in a deep, noncache-coherent memory hierarchy with widely varying access latencies and bandwidth.
In this paper, we introduce HetExchange-a parallel query execution framework that encapsulates the heterogeneous parallelism of modern multi-CPU-multi-GPU servers and enables the parallelization of (pre-)existing sequential relational operators. In contrast to the interpreted nature of traditional Exchange, HetExchange is designed to be used in conjunction with JIT compiled engines in order to allow a tight integration with the proposed operators and generation of efficient code for heterogeneous hardware. We validate the applicability and efficiency of our design by building a prototype that can operate over both CPUs and GPUs, and enables its operators to be parallelism- and data-location-agnostic. In doing so, we show that efficiently exploiting CPU-GPU parallelism can provide 2.8x and 6.4x improvement in performance compared to state-of-the-art CPU-based and GPU-based DBMS.
In the last years, modern servers are adopting hardware accelerators, such as GPUs, in order to improve their power efficiency and computational capacity. Modern analytical query processing engines are highly optimized for multi-core multi-CPU query execution, but lack the necessary abstractions to support concurrent hardware-conscious query execution over multiple heterogeneous devices and exploit the available accelerators.
This work presents a Heterogeneity-conscious Analytical query Processing Engine (HAPE), a blueprint for hardware-conscious analytical engines for efficient and concurrent multi-CPU multi-GPU query execution. HAPE decomposes query execution on heterogeneous hardware into, 1) efficient single-device and 2) concurrent multi-device query execution. It uses hardware-conscious algorithms designed for single-device execution and combines them into efficient intra-device hardware-conscious execution modules, via code generation. HAPE combines these modules to achieve multi-device execution by handling data and control transfers.
We validate our design by building a prototype and evaluating its performance using radix-join co-processing and the TPC-H benchmark. We show that it achieves up to 10x and 3.5x speed-up on the radix-join against CPU and GPU alternatives, respectively, and 1.6x-8x against state-of-the-art CPU- and GPU-based commercial DBMSs on the selected TPC-H queries.
Industry and academia are continuously becoming more data-driven and data-intensive, relying on the analysis of a wide variety of heterogeneous datasets to gain insights. The different data models and formats pose a significant challenge on performing analysis over a combination of diverse datasets. Serving all queries using a single, general-purpose query engine is slow. On the other hand, using a specialized engine for each heterogeneous dataset increases complexity: queries touching a combination of datasets require an integration layer over the different engines.
This paper presents a system design that natively supports heterogeneous data formats and also minimizes query execution times. For multi-format support, the design uses an expressive query algebra which enables operations over various data models. For minimal execution times, it uses a code generation mechanism to mimic the system and storage most appropriate to answer a query fast. We validate our design by building Proteus, a query engine which natively supports queries over CSV, JSON, and relational binary data, and which specializes itself to each query, dataset, and workload via code generation. Proteus outperforms state-of-the-art opensource and commercial systems on both synthetic and real-world workloads without being tied to a single data model or format, all while exposing users to a single query interface.
As the size of data and its heterogeneity increase, traditional database system architecture becomes an obstacle to data analysis. Integrating and ingesting (loading) data into databases is quickly becoming a bottleneck in face of massive data as well as increasingly heterogeneous data formats. Still, state-of-the-art approaches typically rely on copying and transforming data into one (or few) repositories. Queries, on the other hand, are often ad-hoc and supported by pre-cooked operators which are not adaptive enough to optimize access to data. As data formats and queries increasingly vary, there is a need to depart from the current status quo of static query processing primitives and build dynamic, fully adaptive architectures.
We build ViDa, a system which reads data in its raw format and processes queries using adaptive, just-in-time operators. Our key insight is use of virtualization, i.e., abstracting data and manipulating it regardless of its original format, and dynamic generation of operators. ViDa’s queryengine is generated just-in-time; its caches and its query operators adapt to the current query and the workload, while also treating raw datasets as its native storage structures. Finally, ViDa features a language expressive enough to support heterogeneous data models, and to which existing languages can be translated. Users therefore have the power to choose the language best suited for an analysis.